
Webアーカイブというものをずっと前から知っていましたが、特に見る用事もなく、また自分の書いた文章なども記録されてしまう可能性があるので若干怖くもあり、あまり身近には感じていませんでした。
今回はWebアーカイブについて楽しんで、そういう気持ちを払拭してみようかなあと思い、タイムカプセルのような使い方をして、楽しんでみたいと思います。
Webアーカイブとは
Webページはインターネット上に兆単位で存在するといわれ、内容は同じURLでも絶えず変化しています。そのような膨大なデータを保存することは、過去の情報を参照できるようになるとともに、タイムカプセル的な価値があるわけです。
そこで、Webアーカイブでは、絶えず主要なWebサイトを中心にページのデータを保存しています。簡単に言えば、保存さえ行われていれば過去のネットの姿を見ることが可能なのです。
こういう試みは20年ほど前からあります。ですから、最古のものだと1996年くらいのページを見ることができます。20年前といえばインターネットのまだ短いタイムラインから見てもとても古く、地球の歴史で言えばまだバクテリアくらいしかいないんじゃないでしょうか(よくわからないで言ってる)。
ということで、ネットの古代の姿を見てみましょう。
方法
その手のサービスはいくつかありますが、今回はこちらを使用します。
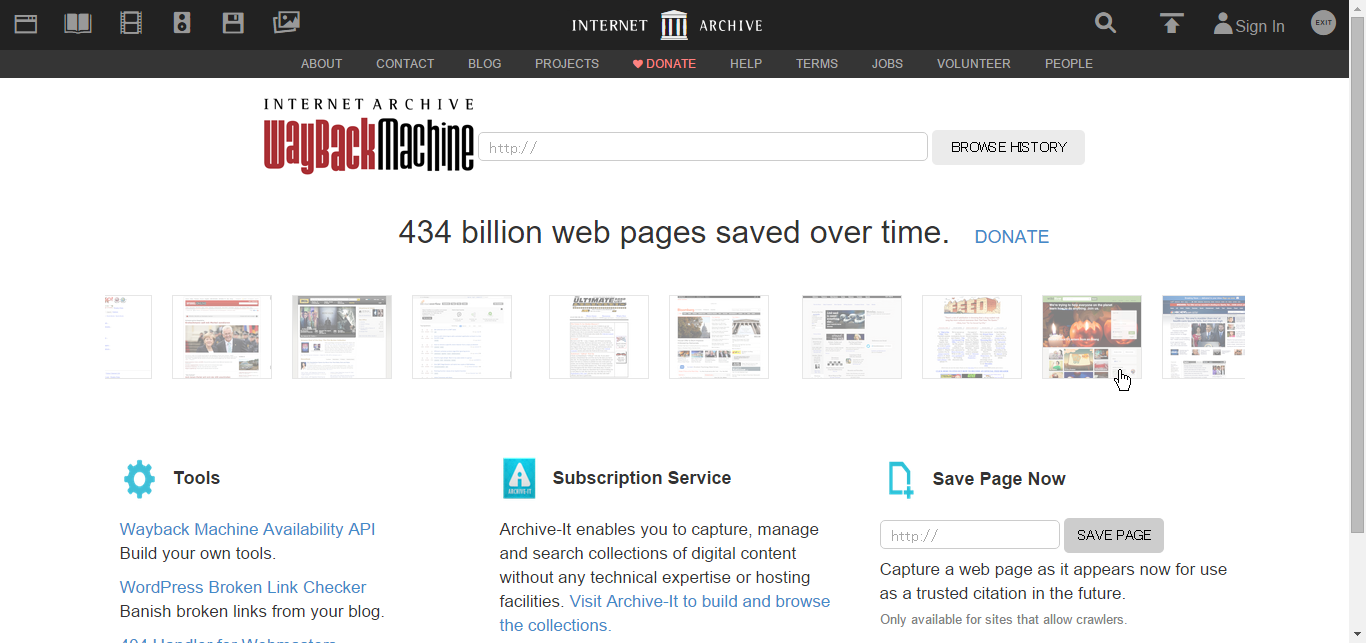
Internet Archive: Wayback Machine
このページにアクセスしたら、見たいURLを入力して「BROWSE HISTORY」をクリックします。URLは、見たいサイトのアドレスバーをコピーして貼り付けてください。
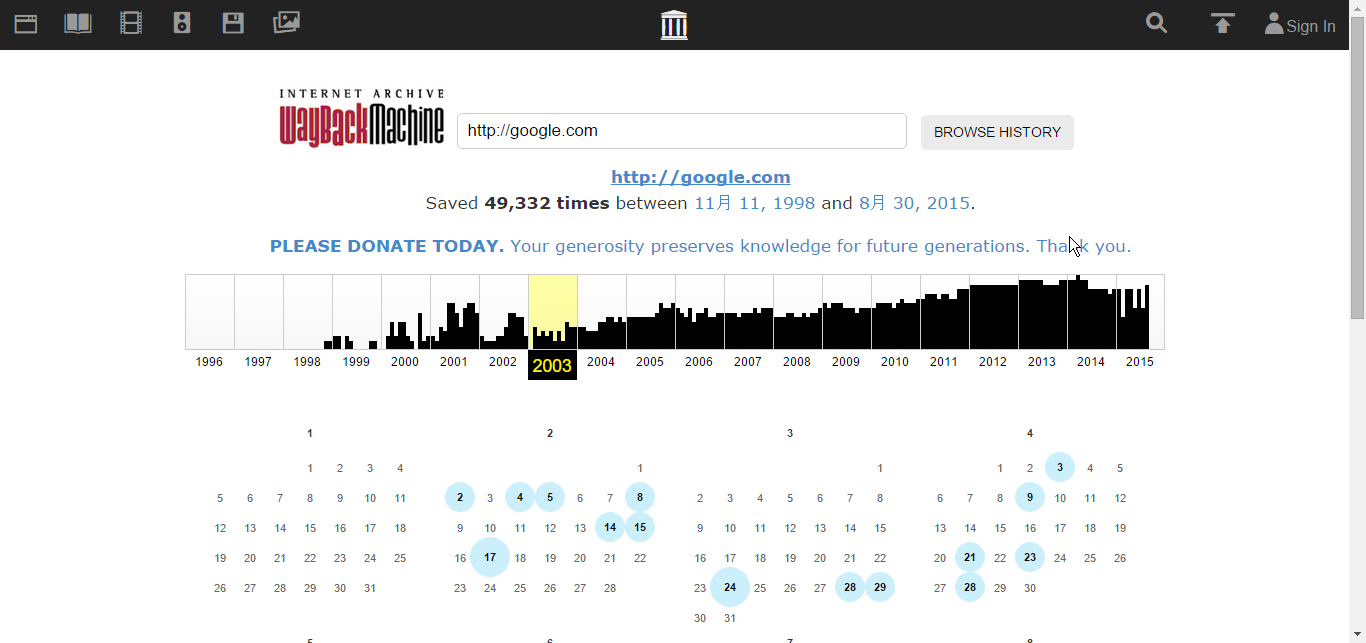
その後、カレンダーが表示されます。青い丸がある部分がデータのあるところで、濃くて大きいほどその日にとられたデータが多いことを表します。年を変えるにはもちろん上のグラフみたいなところをクリック。
青い丸をクリックすれば、その日のアーカイブが見られるというわけです。それでは、実際に何かやってみましょう。
タイムトラベルをした気になる
まあ、ランダムにWebサイトを挙げよと言われて思いつくのはなぜかGoogle先生ですから(その時点でランダムではないけど)、まずはGoogleでやってみますか。

最も古いのは1998年11月11日。約17年前ですね。Webではカンブリア紀くらい(適当)。ちなみにGoogleの創業は同年9月4日なので、本当に始まって間もないということ。
実際に見てみると、こうなります。
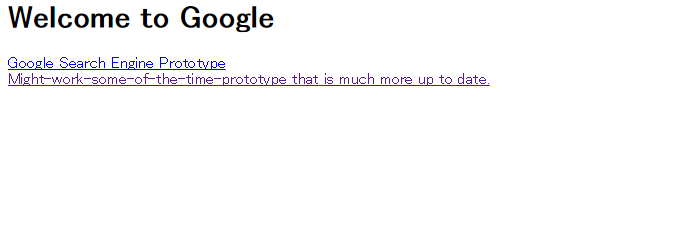
「Welcome to Google」の文字と、リンクが2つ。「Google Search Engine Prototype」…つまり、Google検索が構想段階ということ。現代にGoogleは必要不可欠のような気もしますが、無い時代もあったんですね(あたりまえ)。
「Google Search Engine Prototype」のリンクをクリックすると、こうなります。
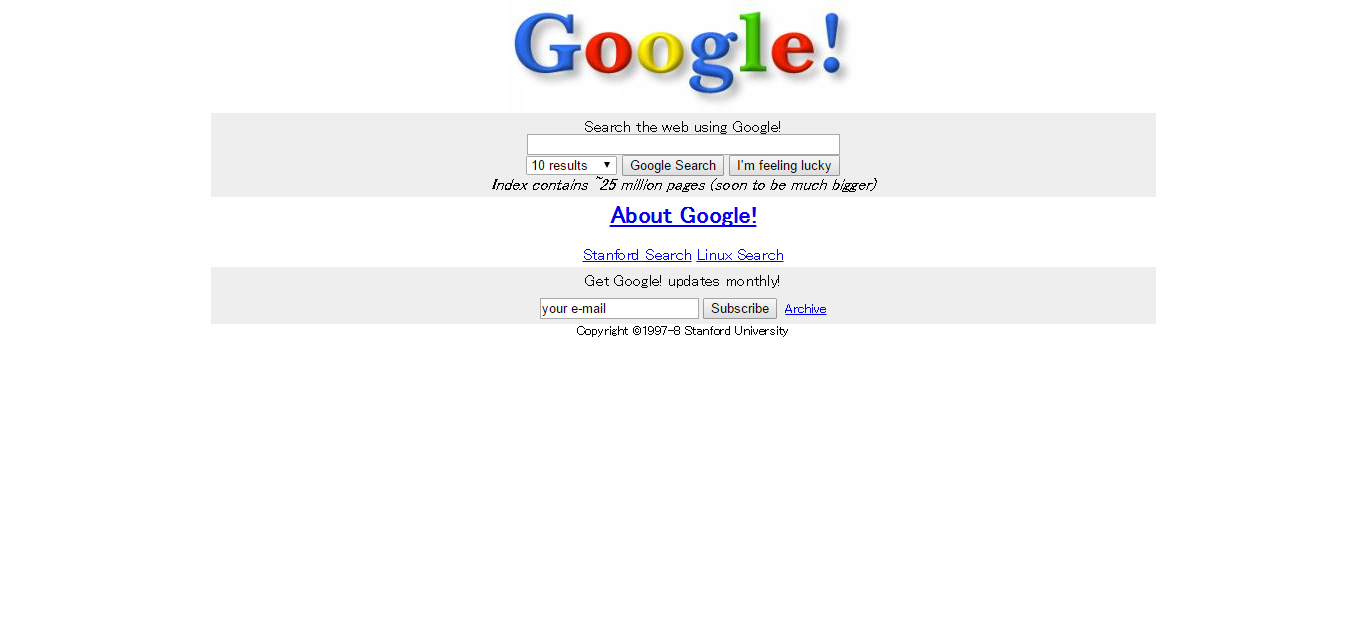
今とそんなに機能は変わらないように見えます。ただ、内部でどのように検索結果がランク付けされるのかというアルゴリズムの向上をここから常に続けていくことになるというのは、言うまでもありません。
また、「Index contains ~25 million pages」とあります。既に2500万ページまではクロールしているということになりますね。これでも多いような気もしますが、今はその50万倍以上にもなっているのですよ。途方もない数字…
あ、もちろんWebアーカイブは、URLに対して返されてくる静的なページを保存するだけなので、検索エンジン自体などプログラムを保存することは当然できません(できたらセキュリティ上ヤバすぎる)。ですから、このページの検索は使えないのでお間違えなく。
Yahoo!JAPAN
日本のサイトも見てみましょう。
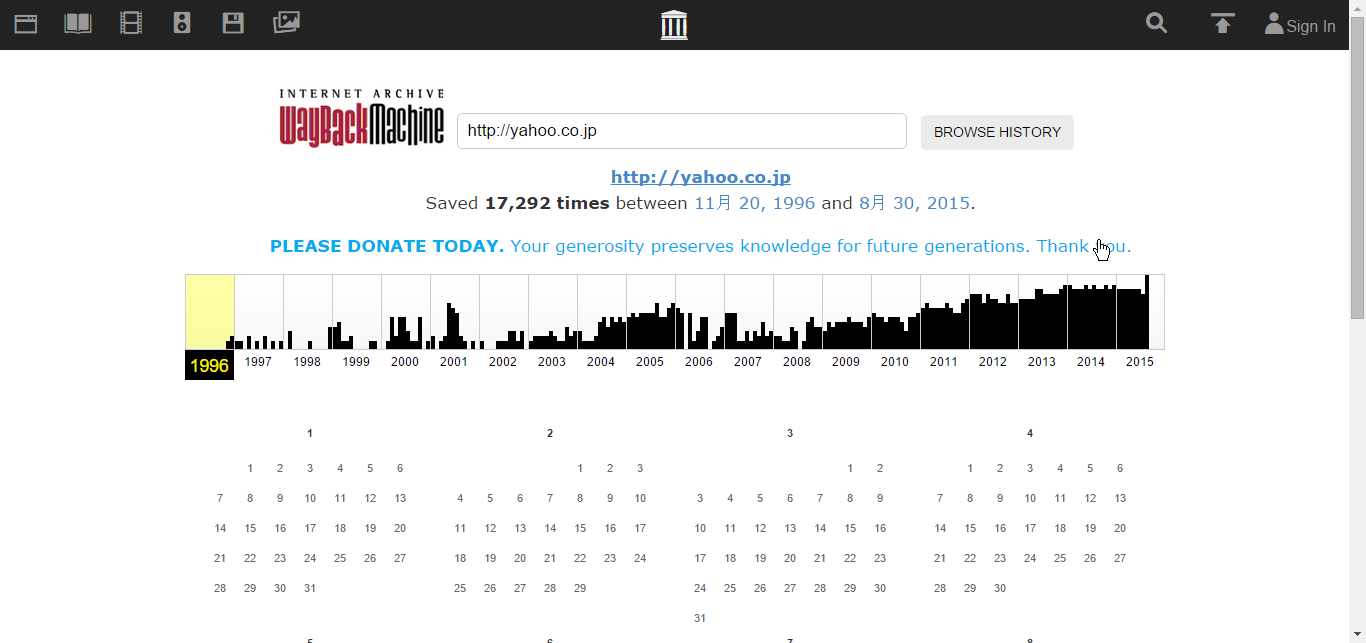
なんとこれは、Googleのアーカイブよりもさらに2年も古い1996年の11月20日のものが残っています!

見てみると、非常にそっけないですね。それもそのはず、デザインが設定されておらず、当然段組みもないので、ワープロソフトで書くことができる程度のビジュアルになります。
画像も非常に荒いものになっています。今でこそ一瞬で表示されますが、この時代はおそらくダイヤルアップなので、そのクオリティを追求するまでもなく。
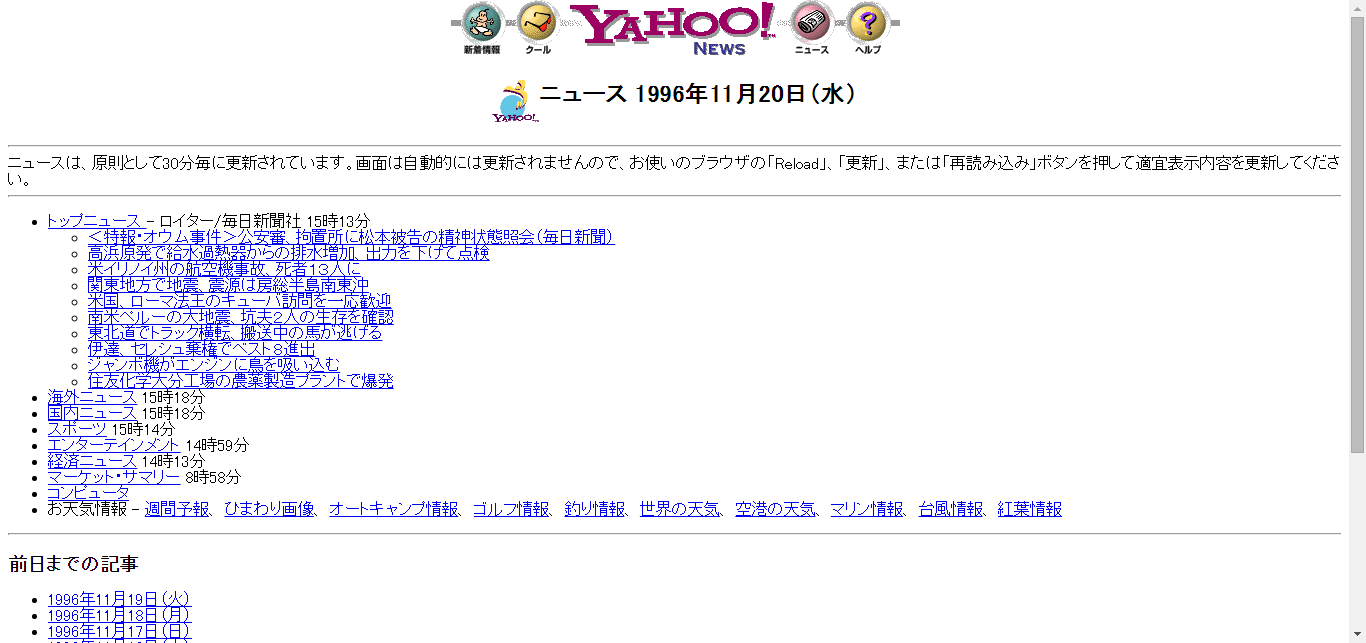
ニュースを見てみると…うーん、あまり長期の記録には残っていないようなニュースも眠っているかもしれませんね。
YouTube
コミュニティでも見てみようかということで、YouTubeを見て終わります。こちらは2005年4月28日が最古です。

会員制だったんでしょうか?よくわかりませんが、「VIDEOS」をクリック。

すると、こういう画面になりました。この画面は、その時のアーカイブが保存されていなかったので、もっとも近いアーカイブにリダイレクトしているみたいなことのようです。
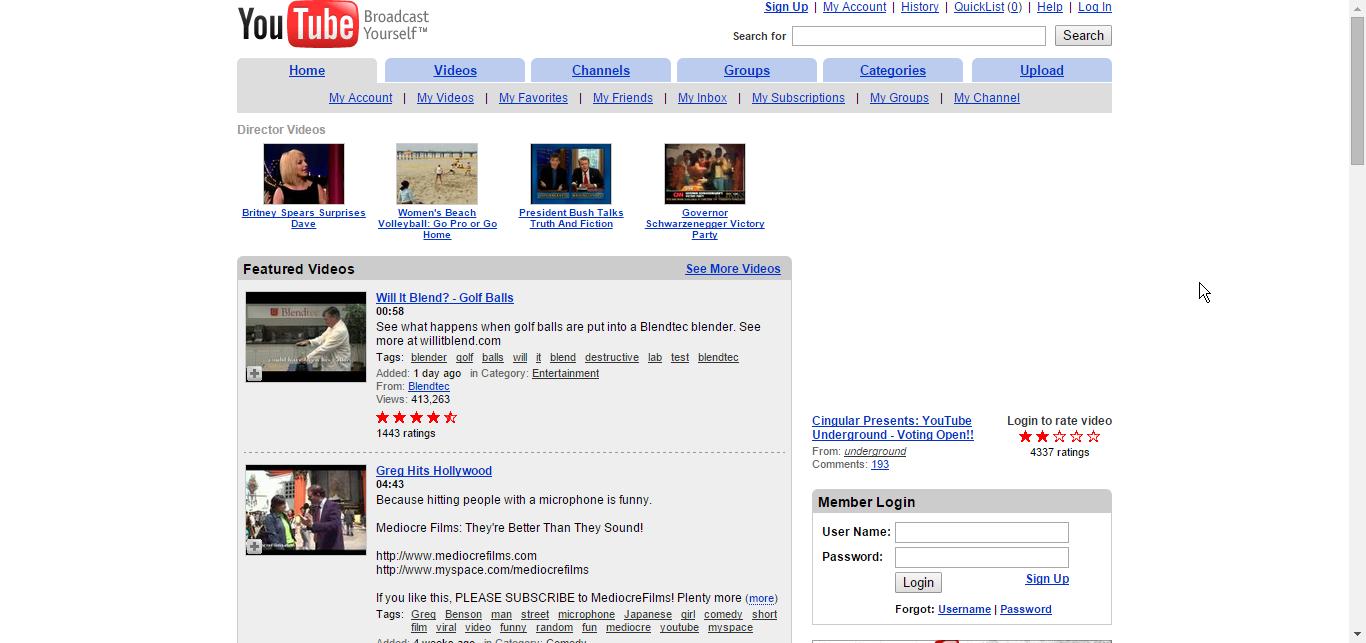
すると、2006年11月9日まで進められてしまいました。まあいいか…。って、最初の動画の人見覚えあるぞ。今後iPhoneなどをゴリゴリ削ることになるとは、まだ誰も知らなかった。
著作権的に大丈夫なの?
と、ただの面白記事で終わってもいいのですが、ふと思ったのが、アーカイブは他人の著作物をコピーした上にさらに配布しているのにもかかわらず、許されているのかということです。
単刀直入に言えば、特に問題ないのですが、何故でしょうか。
インターネットアーカイブがこれほど大規模にウェブアーカイブを構築できるのはフェアユースに基づいているからです。米国では著作権にフェアユースと呼ばれる規定があります。著作物を利用する場合に、それが公正な利用であれば著作権の侵害には当たりません。その規定を基にWayback Machineは運営されています。
フェアユースとなる「公正な利用」というのは非常にふわっとした表現ですが、要は利用目的が非営利の教育用であったり、原作の売り上げに影響を与えないようになっているといったことであれば良いということらしいです。
終わりに
少しだけ見てみましたが、アーカイブされているページは数千億に上るといわれ、データ量で言えばペタという単位の世界のようです。テキストだけでそれまでになるとは…一生かけても見切れる気がしませんね。
埋もれたニュースがあったり、人々の活動した痕跡があったりと、どこか物悲しさも感じられます。この記事ももしかしたら10年後に見返すと、こんな荒い画像しか使えなかったのか、とかなるんでしょうかね…いや、そろそろコンピュータの処理能力は人間の知覚の限界に近づいていると思うのでそれはないか。